[C50] FFNeRV: Flow-Guided Frame-Wise Neural Representations for Videos
Abstract
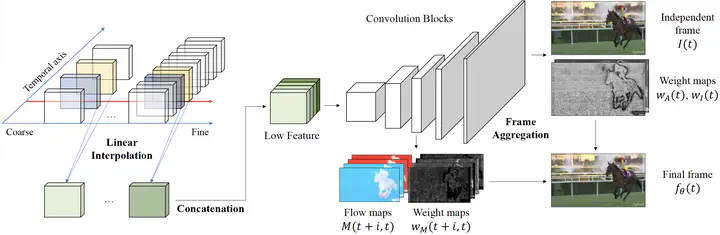
Neural fields, also known as coordinate-based or implicit neural representations, have shown a remarkable capability of representing, generating, and manipulating various forms of signals. For video representations, however, mapping pixel-wise coordinates to RGB colors has shown relatively low compression performance and slow convergence and inference speed. Frame-wise video representation, which maps a temporal coordinate to its entire frame, has recently emerged as an alternative method to represent videos, improving compression rates and encoding speed. While promising, it has still failed to reach the performance of state-of-the-art video compression algorithms. In this work, we propose FFNeRV, a novel method for incorporating flow information into frame-wise representations to exploit the temporal redundancy across the frames in videos inspired by the standard video codecs. Furthermore, we introduce a fully convolutional architecture, enabled by one-dimensional temporal grids, improving the continuity of spatial features. Experimental results show that FFNeRV yields the best performance for video compression and frame interpolation among the methods using frame-wise representations or neural fields. To reduce the model size even further, we devise a more compact convolutional architecture using the group and pointwise convolutions. With model compression techniques, including quantization-aware training and entropy coding, FFNeRV outperforms widely-used standard video codecs (H.264 and HEVC) and performs on par with state-of-the-art video compression algorithms.