[C10] On-Chip Training of Recurrent Neural Networks with Limited Numerical Precision
Abstract
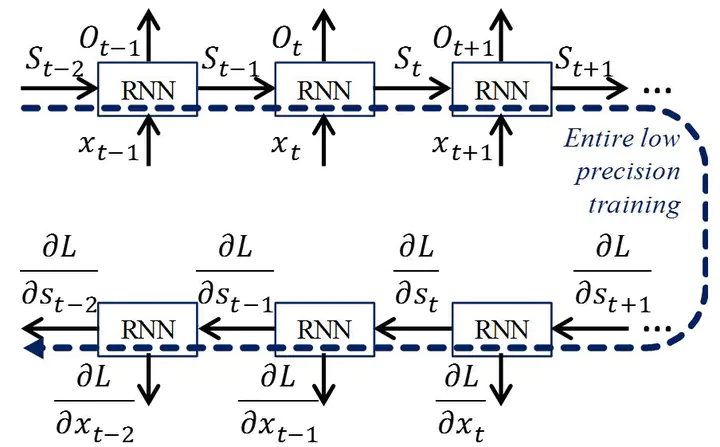
Training of neural network can be accelerated by limited numerical precision together with specialized low-precision hardware. This paper studies how low precision can impact on entire training of RNNs. We emulate low precision training for recently proposed gated recurrent unit (GRU) and use dynamic fixed point as a target numeric format. We first show that batch normalization on input sequences can help speed up training with low precision as well as high precision. We also show that the overflow rate should be carefully controlled for dynamic fixed point. We study low precision training with various rounding options including bit truncation, round to nearest, and stochastic rounding. Stochastic rounding shows superior results than the other options. The effect of fully low precision training is also analyzed by comparing partial low precision training. We show that the piecewise linear activation function with stochastic rounding can achieve comparable training results with floating point precision. Low precision multiplier and accumulator (MAC) with linear-feedback shift register (LFSR) is implemented with 28nm Synopsys PDK for energy and performance analysis. Implementation results show low precision hardware is 4.7x faster, and energy per task is up to 4.55x lower than that of floating point hardware.