[C39] Element-wise Partial Product Quantization for Efficient Deep Learning Accelerators
Abstract
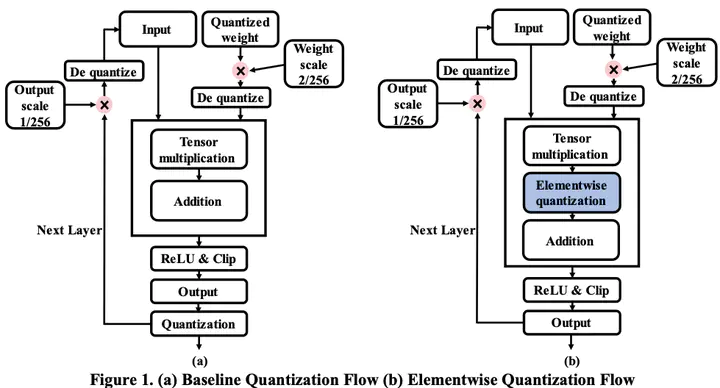
For efficient DNN edge computing, the model inference must be performed quickly while reducing memory requirement and computation. To this end, deep learning quantization algorithms and dedicated accelerators are actively studied. However, in previous studies, algorithms and accelerators are not co-optimized, requiring complex high-precision operations when processing them in accelerators, or additional resources to store intermediate computation results. To address these problems, we propose a novel quantization algorithm named element-wise quantization and a co-optimized accelerator design. We apply quantization directly to the element-wise partial product results of DNN parameters. Through this process, the size of the intermediate values generated in the inference process is reduced, allowing the accelerator to process it using fewer resources. We fix all the floating-point parameters of the quantization process in the form of power of 2 so that the accelerator can efficiently process them. Through SW-HW cooptimization, we can efficiently process model inference using only integer operation while saving 13.5%, 7.5%, and 15% on Flip flops, LUTs, and I/Os respectively, with only 3~4% accuracy loss.