[C47] Kernel Shape Control for Row-Efficient Convolution on Processing-In-Memory Arrays
Abstract
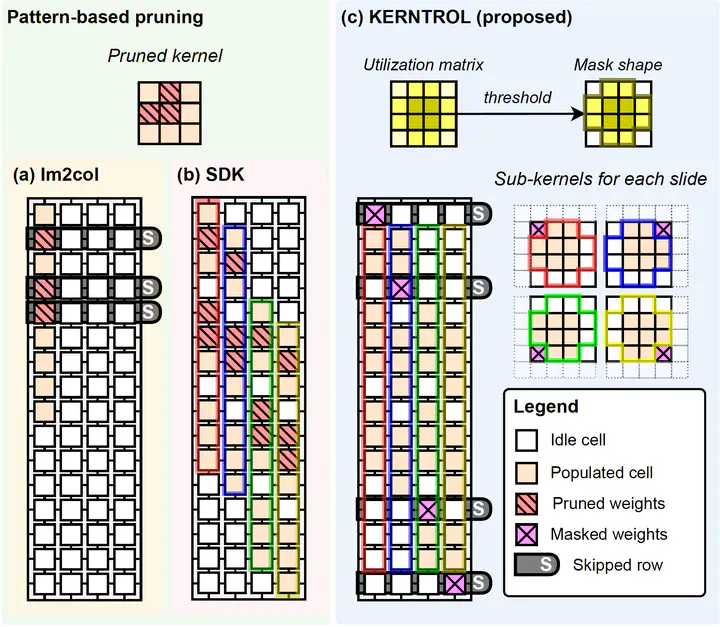
Processing-in-memory (PIM) architectures have been highlighted as one of the viable solutions for faster and more power-efficient convolutional neural networks (CNNs) inference. Recently, shift and duplicate kernel (SDK) convolutional weight mapping scheme was proposed, achieving up to 50% throughput improvement over the prior arts. However, the traditional pattern-based pruning methods, which were adopted for row-skipping and computing cycle reduction, are not optimal for the latest SDK mapping…
Type
Publication
IEEE/ACM International Conference on Computer-Aided Design 2023