[J16] ORVAE: One-Class Residual Variational Autoencoder for Voice Activity Detection in Noisy Environment
Abstract
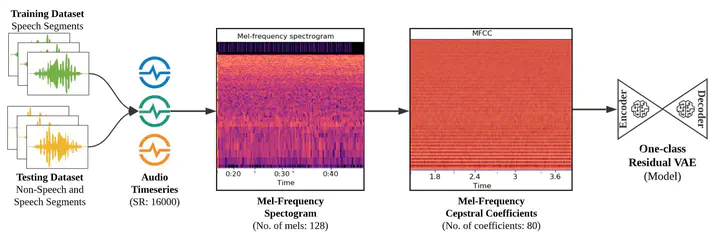
Detecting human speech is foundational for a wide range of emerging intelligent applications. However, accurately detecting human speech is challenging, especially in the presence of unknown noise patterns. Generally, deep learning-based methods have shown to be more robust and accurate than statistical methods and other existing approaches. However, typically creating a noise-robust and more generalized deep learning-based Voice Activity Detection (VAD) system requires the collection of an enormous amount of annotated audio data. In this work, we develop a generalized model trained on limited types of human speeches with noisy backgrounds. Yet, it can detect human speech in the presence of various unseen noise types, which were not present in the training set. To achieve this, we propose a One-Class Residual connections-based Variational Autoencoder (ORVAE), which only requires a limited number of human speech data with noisy background for training, thereby eliminating the need for collecting data with diverse noise patterns. Evaluating ORVAE with three different datasets (synthesized TIMIT and NOISEX-92, synthesized LibriSpeech and NOISEX-92, and a Publicly Recorded dataset), our method outperforms other one-class baseline methods, achieving F1-scores of over 90% for multiple Signal-to-Noise Ratio (SNR) levels.