[C44] Weight-Aware Activation Mapping for Energy-Efficient Convolution on PIM Arrays
Abstract
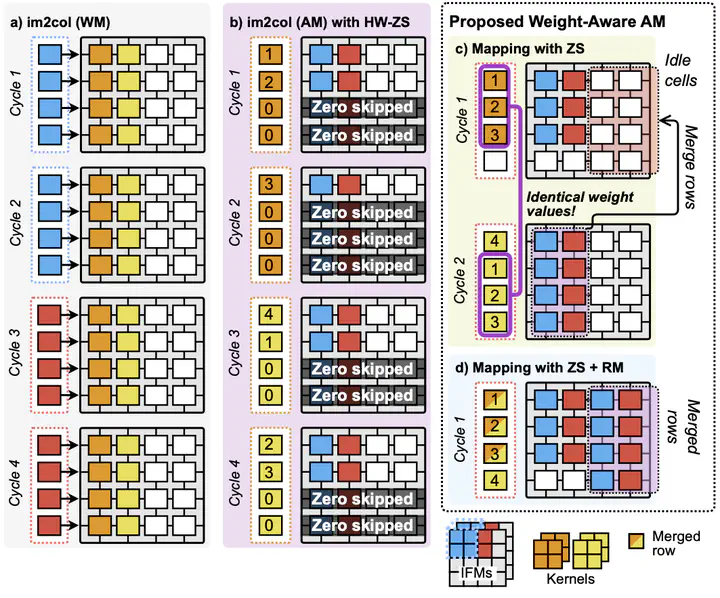
Convolutional weight mapping plays a stapling role in facilitating convolution operations on Processing-in-memory (PIM) architecture which is, at its essence, a matrix-vector multiplication (MVM) accelerator. Despite its importance, convolutional mapping methods are under-studied and existing mapping methods fail to exploit the sparse and redundant characteristics of heavily quantized convolutional weights, leading to low array utilization and redundant computations. To address these issues, this paper proposes a novel weight-aware activation mapping method where activations are mapped onto the memory cells instead of the weights. The proposed method significantly reduces the number of computing cycles by skipping zero weights and merging those PIM array rows with the same weight values. Experimental results on ResNet-18 demonstrate that the proposed weight-aware activation mapping can achieve up to 90% energy saving and latency reduction compared to the conventional approaches.